{kind=link}
Description: PNG image
|
| From: | Koichi Murase |
| Subject: | [PATCH] Implement rehashing for associative arrays (Re: speeding up hash_search?) |
| Date: | Mon, 20 Apr 2020 04:51:56 +0900 |
2020-04-19 23:54 George Jones <fooologist@gmail.com>:
> It looks like hash_search just does a linear walk if array entries
> to find elements in a list.
https://eludom.github.io/blog/20200418/
> and there it is, the linear search walking the list in hash_search()
>
> ```
> [...]
>
> bucket = HASH_BUCKET (string, table, hv);
>
> for (list = table->bucket_array ? table->bucket_array[bucket] : 0; list;
> list = list->next)
> {
> [...]
> ```
The associative arrays in `hashlib.c' are implemented by hash tables
as is clear from its name. The main lookup of hash table algorithm is
done by the following line
bucket = HASH_BUCKET (string, table, hv);
but not by the subsequent linear search. The linear search is just a
workaround for the collision of hashes. As far as the load factor of
the hash table is maintained properly, the linear search is O(1)
because the length of the list is O(1).
2020-04-19 23:54 George Jones <fooologist@gmail.com>:
> This slows down (order N?) new inserts when the number of entries
> gets large.
I looked into `hashlib.c' and found that rehashing is actually not
implemented. I just added a function to perform rehashing, and
the performance has been improved.
> Would there be any interest in merging a patch to add an option for
> making this faster (maybe using b-trees?)
https://eludom.github.io/blog/20200418/
> TODO Look for appropriate in-memory hash insert/lookup functions
> - btrees ?
The B-tree is not the most appropriate option here. The hash table is
more appropriate. The B-tree can be used in the case that we want to
keep the ordering of the keys of associative arrays (e.g. we want to
enumerate items in ascending/descending order). Bash associative
arrays do not ensure the ordering of the items, so the hash table can
be used as a more efficient choice and is already implemented in
`hashlib.c'. We can simply add rehashing.
------------------------------------------------------------------------
I attach a patch `0001-hashlib-Implement-rehash.patch' which
implements the rehashing.
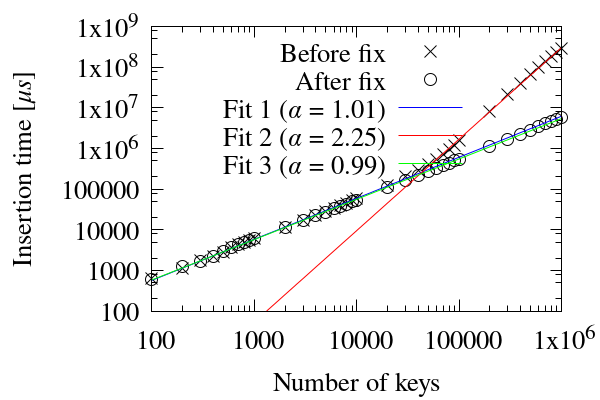
I also tested the performance. The attached `test1.png' shows the
computational time of insertion of items before and after the fix.
The lines are fitted by the function `Time = C Size^alpha' where alpha
is the exponent. Before the fix, there are two regimes depending on
the number of items: linear regime O(N) (alpha ~ 1) and quadratic
regime O(N^2) (alpha ~ 2). The quadratic regime signals the linear
scaling of a single insertion. After the fix, the prformance has been
improved, and the computational time scales linearly in entire region.
I also attach a script `test1.sh' which was used to measure the time.
--
Koichi
![]() test1.png
test1.png
Description: PNG image
![]() 0001-hashlib-Implement-rehash.patch
0001-hashlib-Implement-rehash.patch
Description: Source code patch
![]() test1.sh
test1.sh
Description: Bourne shell script
| [Prev in Thread] | Current Thread | [Next in Thread] |