[Top][All Lists]
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Unicode filenames & "ls"
|
From: |
Bryce Nesbitt |
|
Subject: |
Unicode filenames & "ls" |
|
Date: |
Mon, 17 Sep 2001 10:55:39 -0400 |
All;
I've been experimenting with unicode filenames on my system. I'm using utf-8
(which is the same 8-bit compatible method used by Solaris). It all works
reasonably, but a core program does not cooperate. That program is of
course, "ls".
"ls" has a complex "quoting" mechanism that really destroys the utf-8
sequences. Here's a patch:
HardHat:src> diff ls.c ls.c.v
2630c2630
< size_t len;
---
> size_t len = quotearg_buffer (smallbuf, sizeof smallbuf, name, -1,
options);
2634,2650d2633
<
< // If there's no quoting or string mangling to do, don't do it.
< // The algorithims below will mangle certain multibyte sequences
< // such as Unicode utf-8.
< //
< // xterm -u8 -fn
'-misc-fixed-medium-r-semicondensed--13-120-75-75-c-60-iso1
0646-1'
< // printf("QS:%d", get_quoting_style(NULL));
< if( !get_quoting_style(NULL) )
< {
< displayed_width = strlen(name);
< if (out != NULL)
< fwrite (name, 1, displayed_width, out);
< return displayed_width;
< }
<
< // Actually do something.
< len = quotearg_buffer (smallbuf, sizeof smallbuf, name, -1, options);
And an attached .gif showing the results (in logical Hebrew).
Is there anyone else interested in this issue? Can you suggest a better
way to do this patch?
-Bryce
-------------------------------------------------
PS: Here are some utf-8 references. utf-8 is identical to ascii for ascii
characters. latin-1 characters end up as two bytes. Many unicode
charcters end up as three. All the usual C utilities work great with utf-8,
except that strlen() returns a different length than will be printed, if
there are non-ascii characters present. utf-8 never reuses / or any
other ascii character.
put_utf-8(c)
{
if (c < 0x80) {
putchar (c);
}
else if (c < 0x800) {
putchar (0xC0 | c>>6);
putchar (0x80 | c & 0x3F);
}
else if (c < 0x10000) {
putchar (0xE0 | c>>12);
putchar (0x80 | c>>6 & 0x3F);
putchar (0x80 | c & 0x3F);
}
else if (c < 0x200000) {
putchar (0xF0 | c>>18);
putchar (0x80 | c>>12 & 0x3F);
putchar (0x80 | c>>6 & 0x3F);
putchar (0x80 | c & 0x3F);
}
}
http://czyborra.com/utf/
http://www.cl.cam.ac.uk/~mgk25/unicode.html
 utf-8.gif
utf-8.gif
Description: GIF image
| [Prev in Thread] |
Current Thread |
[Next in Thread] |
- Unicode filenames & "ls",
Bryce Nesbitt <=
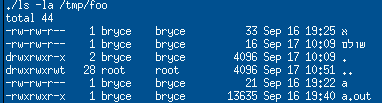{kind=link}