On 11.05.2016 21:09, Federico Larroca
wrote:
Awesome!Hello everyone,We are on the stage of optimizing our project (gr-isdbt).
I have to admit, I'd expect your "simple" for loop doing something likeOne of the most consuming blocks is OFDM synchronization, and in particular the equalization phase. This is simply the division between the input signal and the estimated channel gains (two modestly big arrays of ~5000 complexes for each OFDM symbol).Until now, this was performed by a for loop, so my plan was to change it for a volk function. However, there is no complex division in VOLK. So I've done a rather indirect operation using the property that a/b = a*conj(b)/|b|^2, resulting in six lines of code (a multiply conjugate, a magnitude squared, a deinterleave, a couple of float divisions and an interleave). Obviously the performance gain (measured with the Performance Monitor) is marginal (to be optimistic)...
void yourclass::normalize(std::complex<float> *a, std::complex<float> *b) {
for(size_t idx; idx < a_len; ++idx)
a[idx] /= b[idx];
}
to be neatly optimizable by the compiler, at least if it knows that a and b aren't pointing at the same memory-
Your approach,
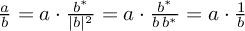
is correct; however, in C++ with std::complex<>
a/bpretty much does that already (ugly std lib C++ ahead, from /usr/include/c++/<version>/complex):
// XXX: This is a grammar school implementation.
template<typename _Tp>
template<typename _Up>
complex<_Tp>&
complex<_Tp>::operator/=(const complex<_Up>& __z)
{
const _Tp __r = _M_real * __z.real() + _M_imag * __z.imag();
const _Tp __n = std::norm(__z);
_M_imag = (_M_imag * __z.real() - _M_real * __z.imag()) / __n;
_M_real = __r / __n;
return *this;
}
And the problem is that while doing that for every a and b
separately might mean you can't make full use of SIMD instructions
to eg. do four complex divisions at once, it avoids having to load
and store original / intermediate values from/to RAM. Basically,
your CPU might not be the bottleneck – RAM could be, and doing
everything you need for a single division at once, even if done
without any optimization, might be faster than incurring additional
memory transfers. That's because your memory controller pre-fetches
whole cache lines worth of values when getting the first elements of
a and b, and working on values from cache is significantly (read:
factor > 50) than a single memory transfer.So, my immediate recommendation really is to keep your loop as minimal as possible, giving your compiler a solid chance to see the potential for optimization. There might not be much you can do. Even hand-written VOLK kernels aren't always faster than automatically generated optimized machine code.
Ha! But it would mean endless (additional) fame!Does anyone has a better idea? Implementing a new kernel is simply out of my knowledge scope.
Soooo: look at the volk_32fc_x2_multiply_conjugate_32fc.h kernel source. Specifically, at the SSE3 implementation, volk_32fc_x2_multiply_conjugate_32fc_u_sse3(…).
You'll notice line 134:
z = _mm_complexconjugatemul_ps(x, y);As you can see, there's a a "VOLK intrinsic",
_mm_complexconjugatemul_pswhich is defined in volk_intrinsics.h. That same file contains _mm_magnitudesquared_ps_sse3 . Maybe you can make something clever out of that :)
Best regards,
Marcus
[1] https://gcc.gnu.org/onlinedocs/gcc/Restricted-Pointers.html